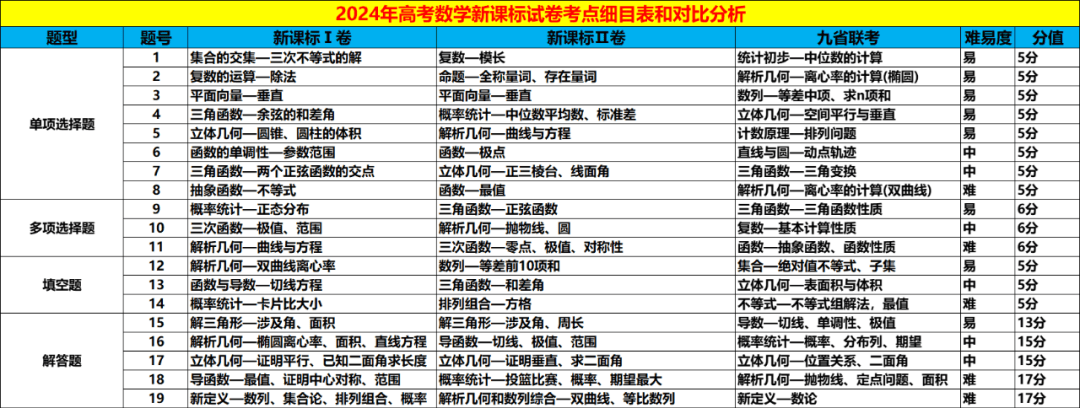
学生的学习成绩受到多种因素的影响,如性别、年龄、家庭背景、学习习惯、学校环境等。为了探索这些因素对学生数学、语言和科学成绩的影响,我们使用了来自葡萄牙两所学校的学生数据集。 数据集介绍:这是一个关于葡
为了对数据集进行数据清洗和可视化处理,可以按照以下步骤进行:
1. 导入数据集:使用适当的编程语言(如Python)导入student-por.csv文件,并将其存储为数据框(DataFrame)。
2. 数据清洗:对数据集进行清洗,包括处理缺失值、异常值和重复值等。可以使用以下方法进行数据清洗:
- 检查并处理缺失值:查看每个变量的缺失值情况,可以使用isnull()函数来检测缺失值,并使用fillna()函数或dropna()函数来处理缺失值。
- 检查并处理异常值:通过绘制箱线图或直方图等可视化方法,检查是否存在异常值,并根据实际情况进行处理,如删除或替换异常值。
- 检查并处理重复值:使用duplicated()函数检测是否存在重复值,并使用drop_duplicates()函数删除重复值。
3. 数据描述统计:对数据集进行描述性统计分析,可以使用以下方法:
- 使用describe()函数生成关于数据集的统计信息,包括均值、标准差、最小值、最大值等。
- 统计每个变量的频数分布,可以使用value_counts()函数。
4. 数据可视化:通过绘制图表来可视化数据集,可以使用以下方法:
- 绘制直方图:对于数值型变量,可以使用直方图来展示其分布情况,可以使用matplotlib或seaborn库中的hist()函数。
- 绘制箱线图:对于数值型变量,可以使用箱线图来展示其分布的五数概括,可以使用matplotlib或seaborn库中的boxplot()函数。
- 绘制条形图:对于分类变量,可以使用条形图来展示其频数分布情况,可以使用matplotlib或seaborn库中的countplot()函数。
通过以上步骤,可以对数据集进行清洗和可视化处理,并对数据进行描述。这样可以更好地理解数据集的特征和分布情况,为后续的数据分析和建模提供基础。
1. 导入数据集:使用适当的编程语言(如Python)导入student-por.csv文件,并将其存储为数据框(DataFrame)。
2. 数据清洗:对数据集进行清洗,包括处理缺失值、异常值和重复值等。可以使用以下方法进行数据清洗:
- 检查并处理缺失值:查看每个变量的缺失值情况,可以使用isnull()函数来检测缺失值,并使用fillna()函数或dropna()函数来处理缺失值。
- 检查并处理异常值:通过绘制箱线图或直方图等可视化方法,检查是否存在异常值,并根据实际情况进行处理,如删除或替换异常值。
- 检查并处理重复值:使用duplicated()函数检测是否存在重复值,并使用drop_duplicates()函数删除重复值。
3. 数据描述统计:对数据集进行描述性统计分析,可以使用以下方法:
- 使用describe()函数生成关于数据集的统计信息,包括均值、标准差、最小值、最大值等。
- 统计每个变量的频数分布,可以使用value_counts()函数。
4. 数据可视化:通过绘制图表来可视化数据集,可以使用以下方法:
- 绘制直方图:对于数值型变量,可以使用直方图来展示其分布情况,可以使用matplotlib或seaborn库中的hist()函数。
- 绘制箱线图:对于数值型变量,可以使用箱线图来展示其分布的五数概括,可以使用matplotlib或seaborn库中的boxplot()函数。
- 绘制条形图:对于分类变量,可以使用条形图来展示其频数分布情况,可以使用matplotlib或seaborn库中的countplot()函数。
通过以上步骤,可以对数据集进行清洗和可视化处理,并对数据进行描述。这样可以更好地理解数据集的特征和分布情况,为后续的数据分析和建模提供基础。